Kahina for QType Tutorial Part 3: Post-Mortem Parse Inspection
This tutorial again only assumes that the project QType Tutorials 1-3 was opened, and that the grammar has already been compiled from within Kahina. The most direct way to match these prerequisites is to follow the instructions in QTypeTutorial1. To understand the discussion in this tutorial, you should also have worked through QTypeTutorial2. After learning there how Kahina can be used much like an ordinary Prolog tracer, in this tutorial you will start to learn how Kahina expands on these capabilities.
A Failing Example Parse
In this chapter, we will be dealing with post-mortem inspection of parses, which is our term for interactively exploring completed traces to find the reasons for failures and other unwanted behavior. To make this task more interesting, we will start by parsing an ungrammatical sentence. Our example will be the sentence uther sleep, which you are now asked to start parsing via the menu entry Grammar -> Parse .... For this toy sentence, it is of course easy to spot that the problem will be the lack of number agreement between the subject and the verb. But using this simple toy example, you will begin to learn how to locate such problems in a QType parse even after the trace was completed, giving you the tools to perform this kind of analysis in less simple cases as well.
Before we can start our post-mortem inspection, we first need to fast-forward through the entire trace by pressing the Leap button and waiting until the parse has finished. This process can take about half a minute, which is arguably very slow for such a short sentence. However, we encourage you not to worry about this too much for now, since for tracing longer sentence you will want to rely on the advanced techniques introduced in later tutorials anyway. The completed parse should consists of 744 steps, which means that the title of your Kahina window should say something like Kahina for Qtype - QType Tutorials 1-3 (744). The contents of the window will look like this:

Unlike in the last tutorial, the red color has infested all branches of the search tree this time, causing a failure of the top-most parsing goal. This is of course what we intended, as it makes the process of analysing the trace quite a bit more interesting by giving us a problem to locate.
Using the Message Console
Before we get our hands dirty, let us summarize the different possibilites Kahina offers for navigating through the steps of a trace. You will already have noticed that almost none of Kahina's numerous view components is purely a display component. Instead, most of the components can also be used for navigation, each having a specific purpose in navigating the step database. Let us start our list with the message console. One important task of the console is to keep track of any non-creep decisions you made while tracing. This information is sometimes essential for understanding the trace behavior afterwards. Without seeing a hint in the message console, one could easily get confused about whether some step failed because none of its clauses applied, or because of a Fail command issued by the user.
Otherwise, the contents of this display component resemble the output of a classical tracer. The difference is that whenever you select a line in the console message, all the other views will be updated to display the position and the details of the involved step. In addition, all the lines associated with the selected step will always be highlighted on the console. The message console will also jump to the event where the step was called for the first time. This allows you to quickly find a linear trace of the step's call environment, which is useful in some situations where the step tree can become a little confusing because of its interacting view dimensions.
Navigating the Step Tree
We have so far avoided to explain how the contents of the step tree are distributed among the overview tree and the detail tree for display. The layering mechanism is intended to split up the tree into meaningful units in order to keep it navigable even if thousands of nodes are involved. The splitting works by configuring certain step types to be treated as corner-stone nodes, which define the context boundaries at which the tree fragments at the display layers are pruned. The detail view always shows the part of the step tree below the corner-stone node that is currently selected in the overview tree, up to and including the next corner-stone nodes.
For QType, calls to the following predicates are pre-configured to be treated as corner-stone nodes because they form the backbone of parsing processes:
| lc/1 | The top-level predicate for left-corner parsing. |
| lc/2 | Driver predicate for left-corner parsing against a prediction, calls the lexicon check. |
| lc/6 | Main worker predicate for left-corner parsing, retrieves lexical entries and makes predictions to be met by lc_complete/8. |
| lc_complete/8 | Fetches rules according to the given left corner, calling lc_list/6 to process the predicted sister constituents. |
| lc_list/5 | Processes predicted left-corner sister constituents, recursively calling lc/6 for this purpse. |
The prime means of navigation in the tree is to select a node at one of the two layers, which will causes the step tree fragments at both layers to adapt, and a display of the step details of the selected step in all the other views. Normally, you will use the overview tree to understand the overall call structure, from time to time selecting corner-stone nodes of interest in order to inspect the intermediate steps in the detail view. When a node in the overview tree is displayed using a bold font, this gives you a visual hint that additional steps can be seen in the detail tree if you select it. The layering mechanism has the sometimes surprising consequence that if you select a corner-stone node in the detail view, the contents of that view will change almost entirely because it now displays the pruned tree fragment headed by the node you selected.
We have not yet mentioned the purpose of the little minus signs you have so far seen next to every step label in the tree. These are a part of the tree display's collapsing mechanism. By double-clicking on any node, you can collapse the call structure under it. The entire call hierarchy under the node will vanish from the tree, and a small + sign will appear instead of the - sign next to the node. This mechanism becomes extremely useful as soon as the tree fragments become so large that the indentation alone will not suffice to understand the call structure. To decollapse a node and restore the call hierarchy below it, you simply double-click on it again.
You are now invited to spend some time fooling around with the step tree, which is always useful for getting a feel for its sometimes complex behavior, and for understanding the ways in which the call tree and the search tree dimensions of the step tree interact. Do not expect do understand everything by only looking at the step tree, you will sometimes need to consult the source code display and the message console in order to fully understand the call structure.
The Selection History
A third possibility to navigate through the step database is to make use of the selection history. Kahina stores a list of the steps which were selected during tracing and/or inspection, and makes it possible to page through this exploration history. The reader should take the opportunity to try out this feature right now, carrying him or her backward and forward through the steps most recently inspected using the other navigation methods. Like in a browser history, selecting a step by some other method will destroy the selection history after current point in the past. For the future, we intend to extend the browser analogy by providing a bookmark function which allows the user to collect links to interesting steps in a separate list for later reference. The buttons for browsing the selection history are the rightmost two buttons in the control panel:

| Back: Goes back one step in the selection history. This button is already active during the first step of a parse or compilation, since it is always possible to go back to the top-level [query] node. If no manual selection was carried out yet, the button can be used to inspect the trace in reverse. | |
| Forward: Goes one step forward in the selection history, which is only possible if a past selection was revisited using the Back button, and no other means of selection was used since the last back step in the history. |
Finding Problems using Post-Mortem Inspection
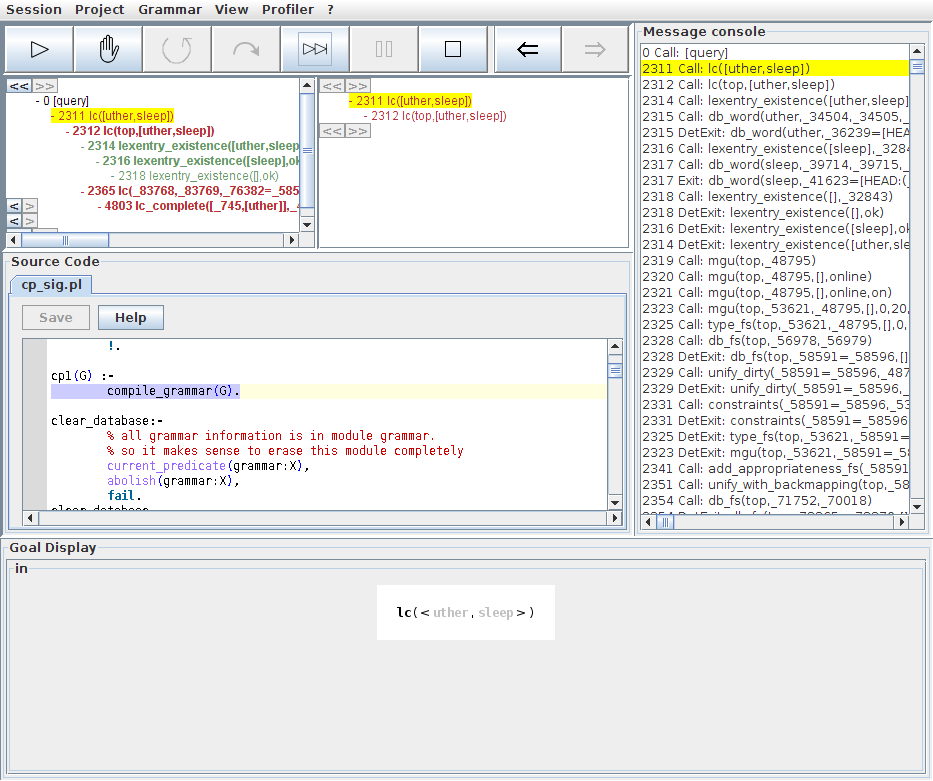
Now that we are more familiar with the different methods of expecting the step database, let us return to our failed parse and learn how to systematically determine what went wrong. First of all, let us select the failed topmost call to lc/6, where we would find the results of a successful parse.

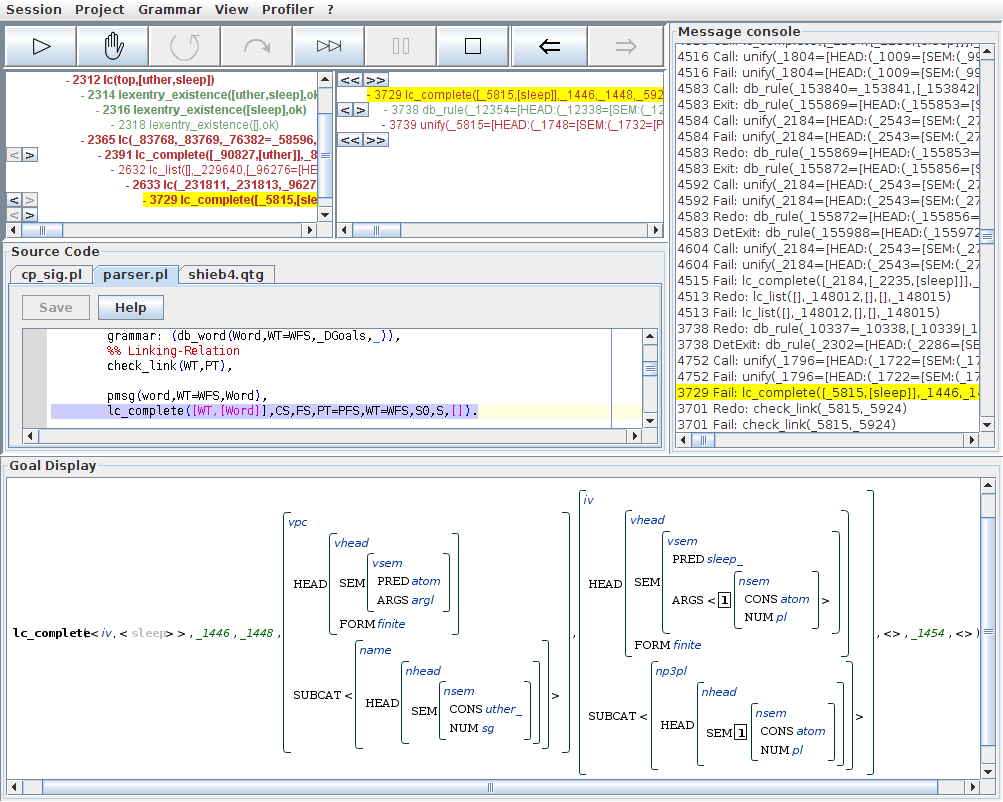
The detail view for this node tells us that QType has successfully retrieved a lexical entry for the word uther. Inspecting the successful call to check_link/2 reveals that the currently selected branch of the search tree tries to build a structure of type s. This is the category we would expect for uther sleep, so let us descend further into this branch of the search tree. We see that the subsequent call to lc_complete/6 has failed, so let us find out why.

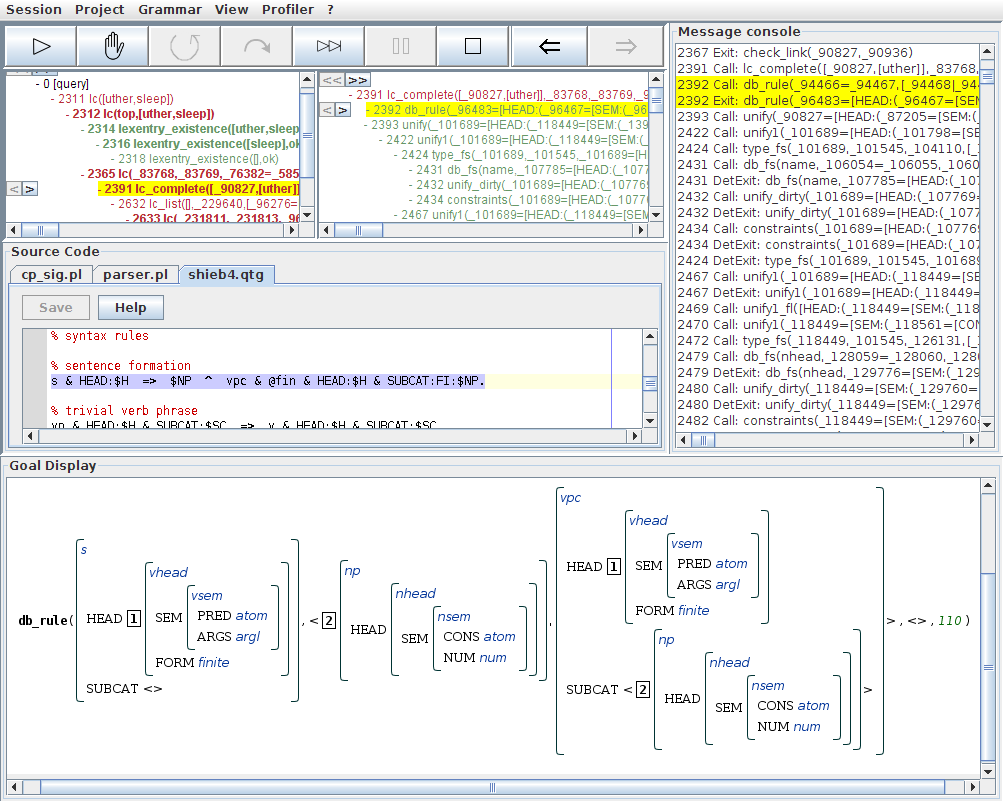
After selecting the failed lc_complete/6 step, the detail view now shows us the computations involved in this failure. We see that the search tree branches directly under this call because QType non-deterministically selected a rule for prediction. So let us find out which rule was explored in the current branch. Selecting the db_rule/4 call, we see in the source code view that QType selected the sentence formation rule first. Note that this will be the case in any situation where we try to complete an {{{s}} constituent, since QType will always try out rules in the order in which they are declared in the grammar.

The goal display shows us a feature structure representation of the retrieved rule. Note that the rule states how a constituent of type s can be assembled from a noun phrase and a verb phrase with that noun phrase on its subcat list. Since this is the rule we would expect to work out, we again now that we are exploring the right branch of the search tree. Otherwise, we would have had to flip through the rules now using the little arrows next to the db_rule/4 call.
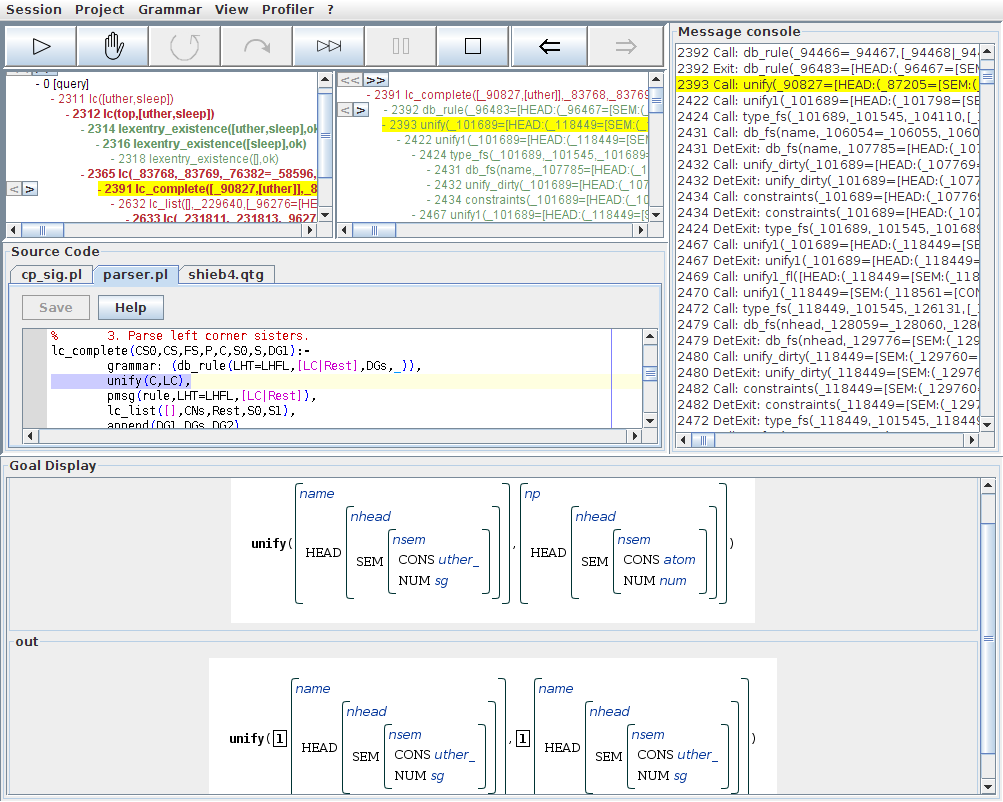
In the next step, lc_complete/6 attempts to unify the current constituent with the head of the selected rule. Inspecting the corresponding call to unify/2 in the detail view, we see in the goal display that the rule's head was successfully unified with our lexical entry for uther. If you are interested in the internals of the unification process, you can inspect some of the steps below this node in the call tree.

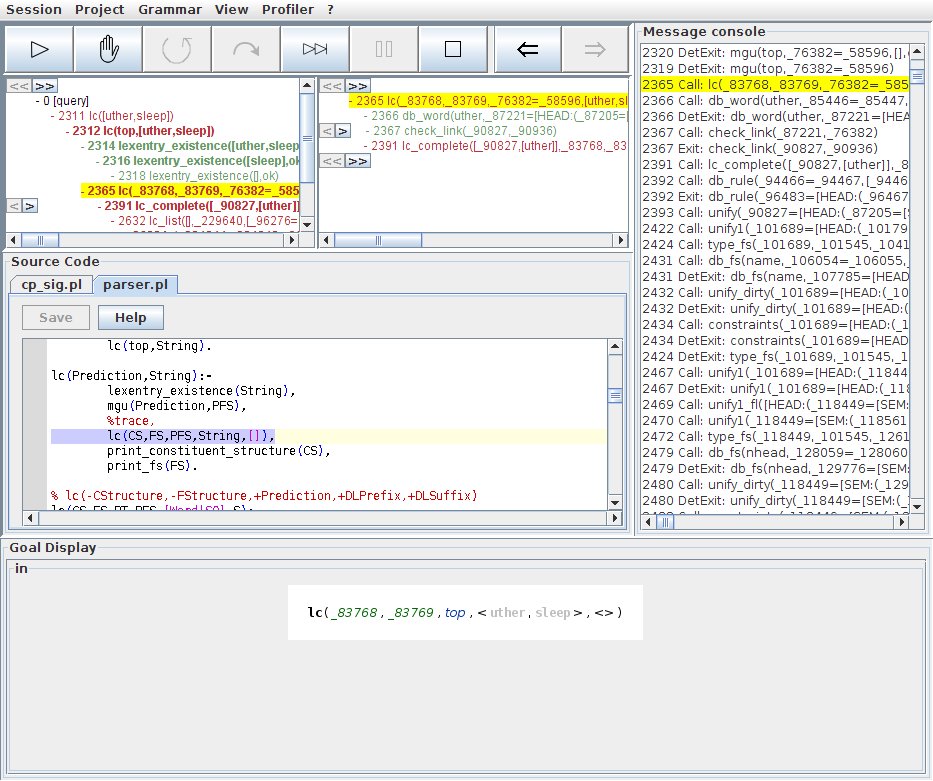
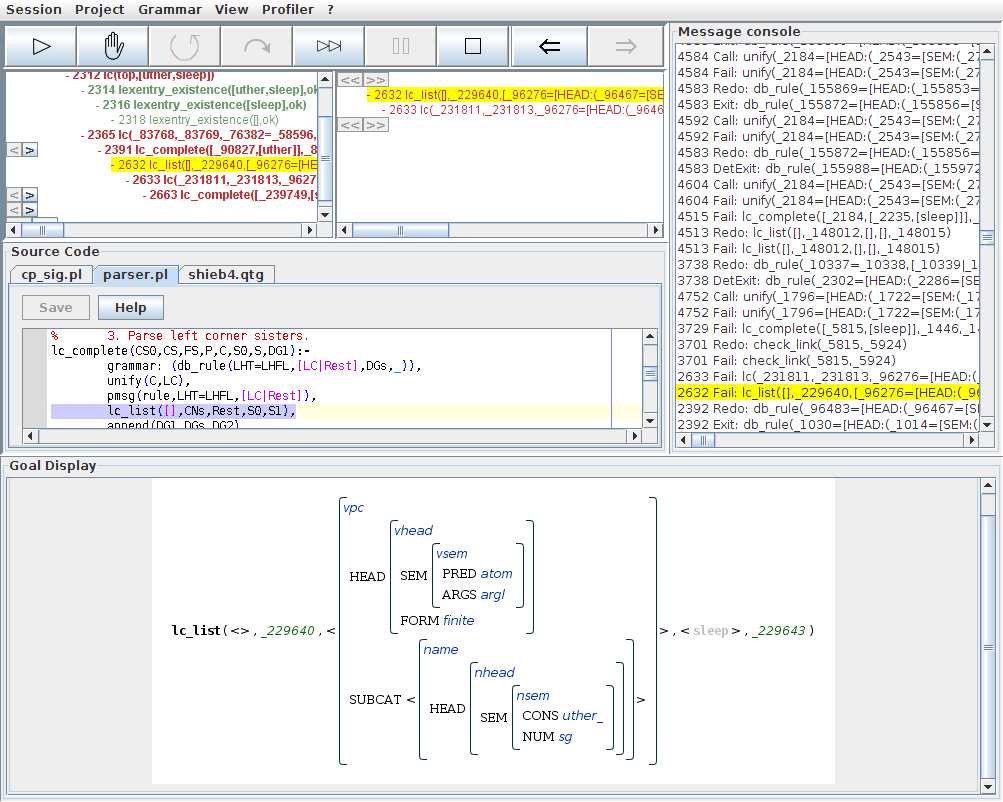
The last subgoal of this lc_complete/6 invocation is another corner-stone node: a call to lc_list/5 with the task of recursively parsing the left-corner sisters predicted by the selected rule. As we see, this call to lc_list/5 has failed, so let us select this step for inspection:

Since the lc_list/5 node was not marked with bold font in the overview tree, it is not surprising that we do not see anything additional in the detail view now. In the goal view, we see that this call has tried to parse sleep as verb phrase which has the already parsed structure for uther as a complement. From the step tree, we know that the reason for the failure of lc_list/5 is that this subparse has failed.
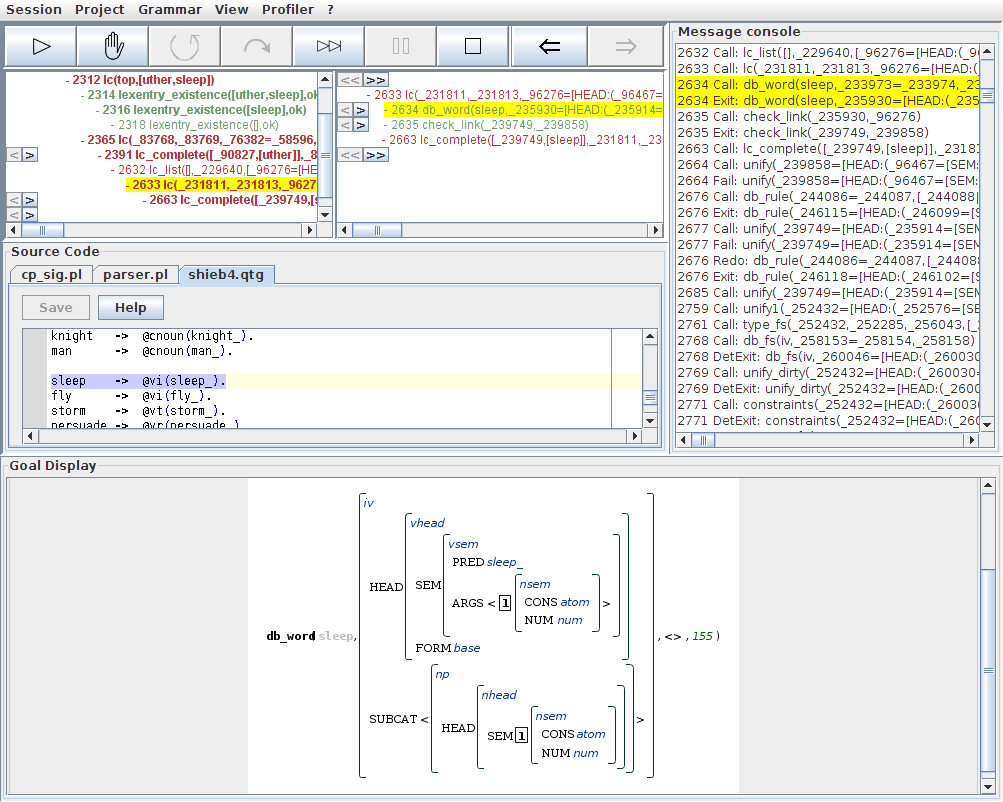
If we select the lc/6 child node, the detail tree shows us that QType successfully retrieved a lexical entry for sleep. An inspection of the db_word/4 step gives us the retrieved feature structure in the second argument of the goal view:

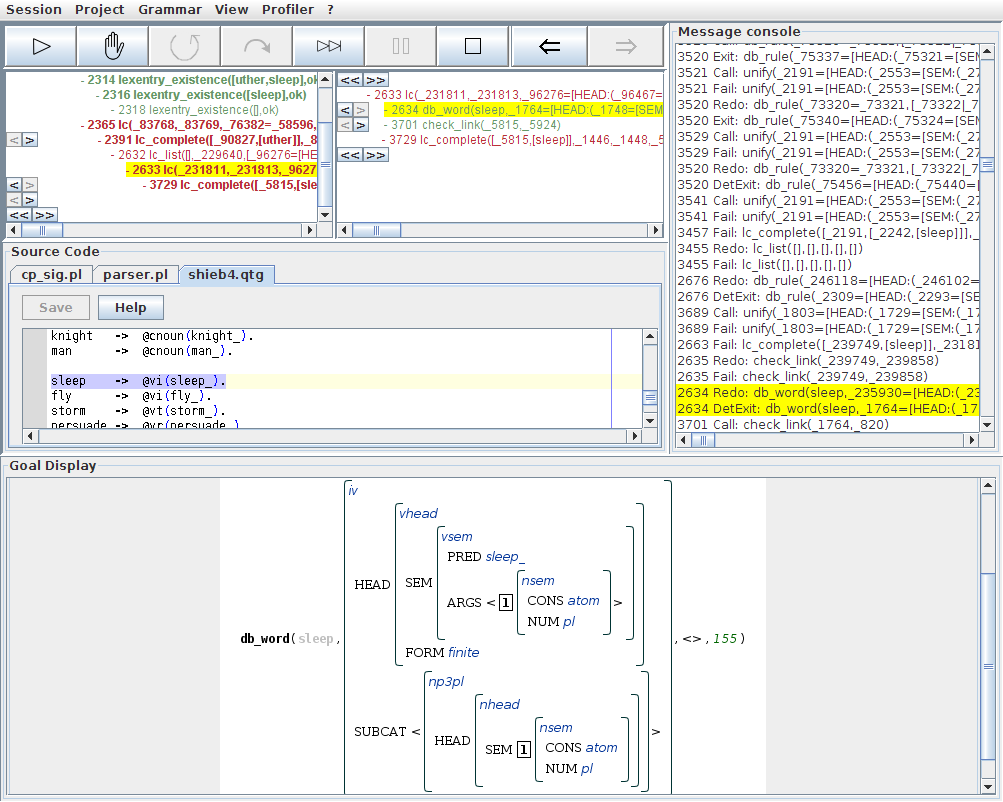
Taking a closer look at this feature structure, the base value of the feature HEAD:FORM tells us that in this branch of the search tree, sleep is treated as a base form. We could follow through this branch to find out why this interpretation ultimately isn't successful, but the more interesting case is covered by the sister branch which we can access by flipping through the possible lexical entries for the form sleep. A click on the arrow to the right next to the db_word/4 step in the detail tree carries us to a search branch which builds on a slightly different feature structure for sleep:

Here, the HEAD:FORM feature has the value finite, and the nsem structure on the argument list has a NUM value of pl, indicating that sleep is now interpreted as a plural form. The step tree shows us that also with this choice, the recursive call to lc_complete/8 fails. Selecting this node, we find that again multiple rules were tried out, all of which failed to yield a vpc parse of sleep with uther as the subject.

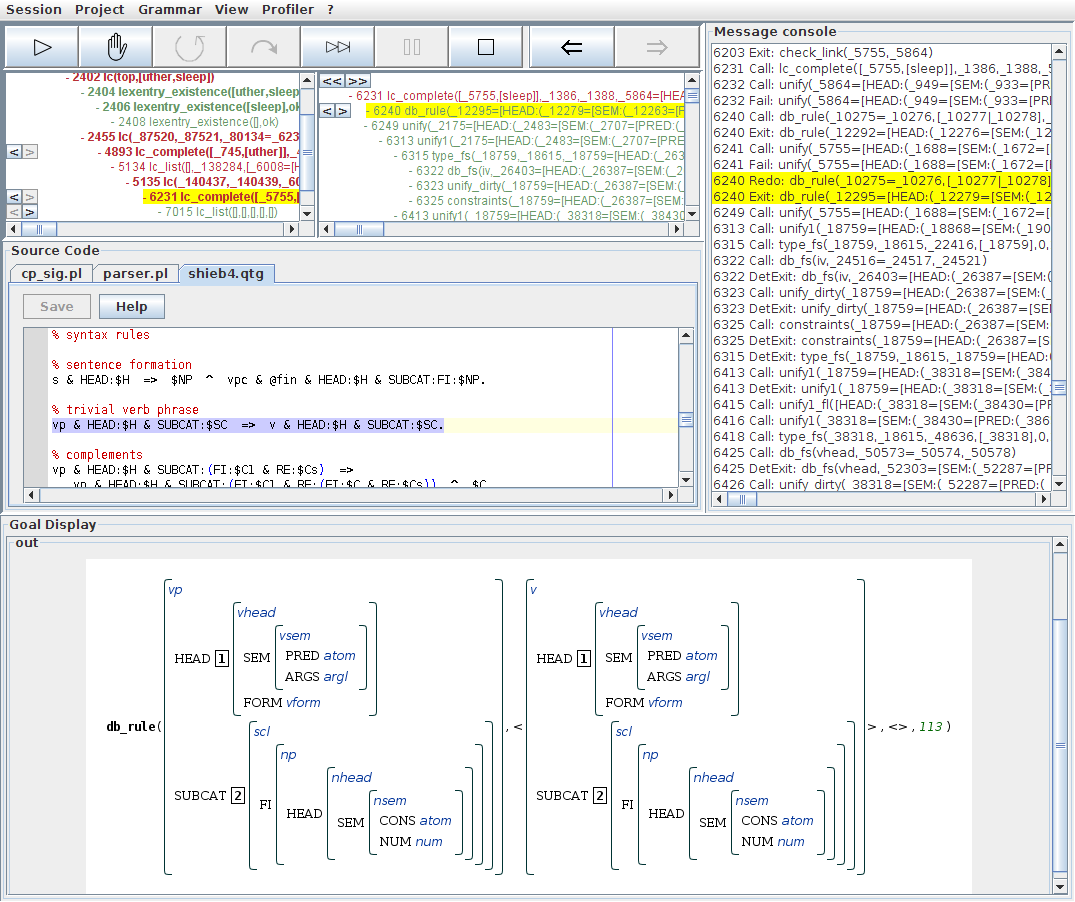
The third alternatives is the most interesting case here, because it tries to build a trivial verb phrase without further complements:

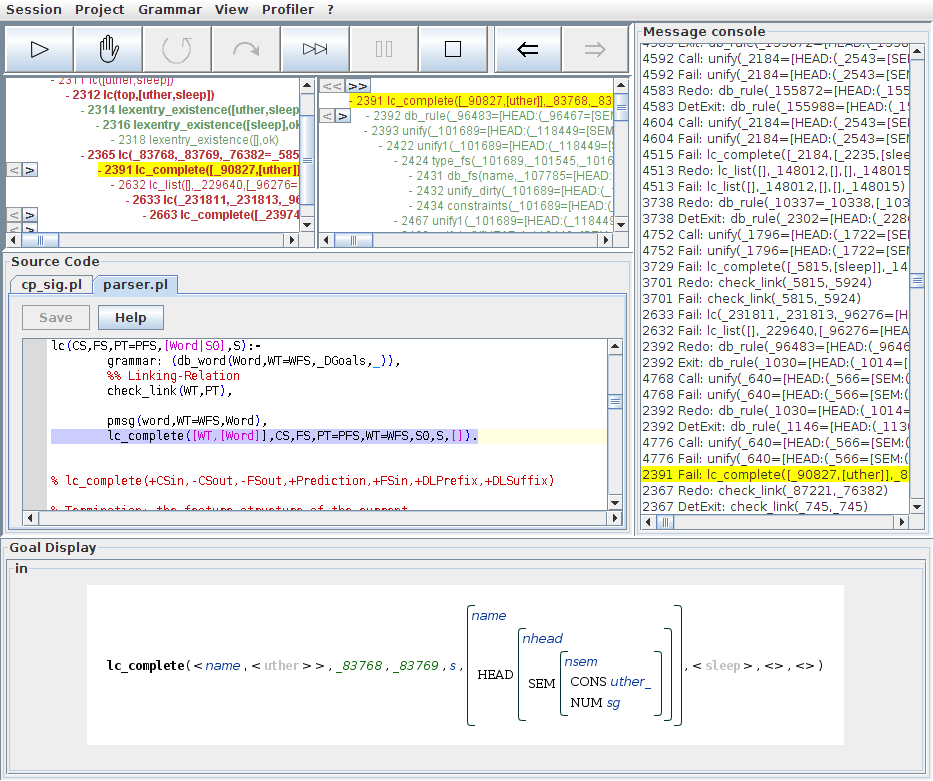
In this case, we can go on because the iv structure derived for the word sleep unifies with the head of the trivial verb phrase rule:

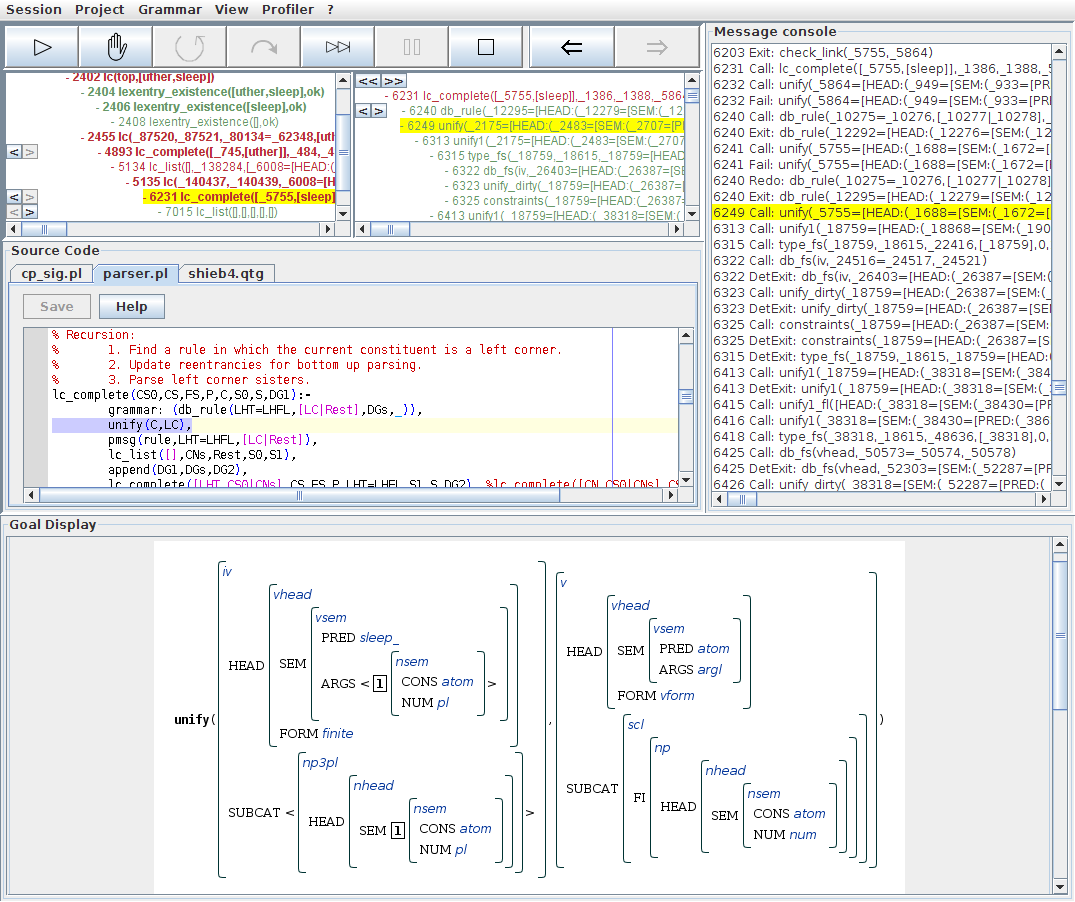
We descend further into this branch by selecting the case where lc_list/5 was successful over the empty list. In a successful parse, for the subsequent recursive call to lc_complete/8 we would now expect the base case to work out, causing us to flip backwards through the alternatives for lc_complete/8 until the first one, where the base case clause was selected. At this point we have isolated the problem, since the necessary unification for the base case fails. An inspection of the failed unify/2 step shows us the problem in the goal view. Since vpc and vp are compatible types, the problem must have been caused by the value clash between sg and pl at the path SUBCAT:HEAD:SEM:NUM, accurately representing the lack of agreement which makes this sentence ungrammatical.

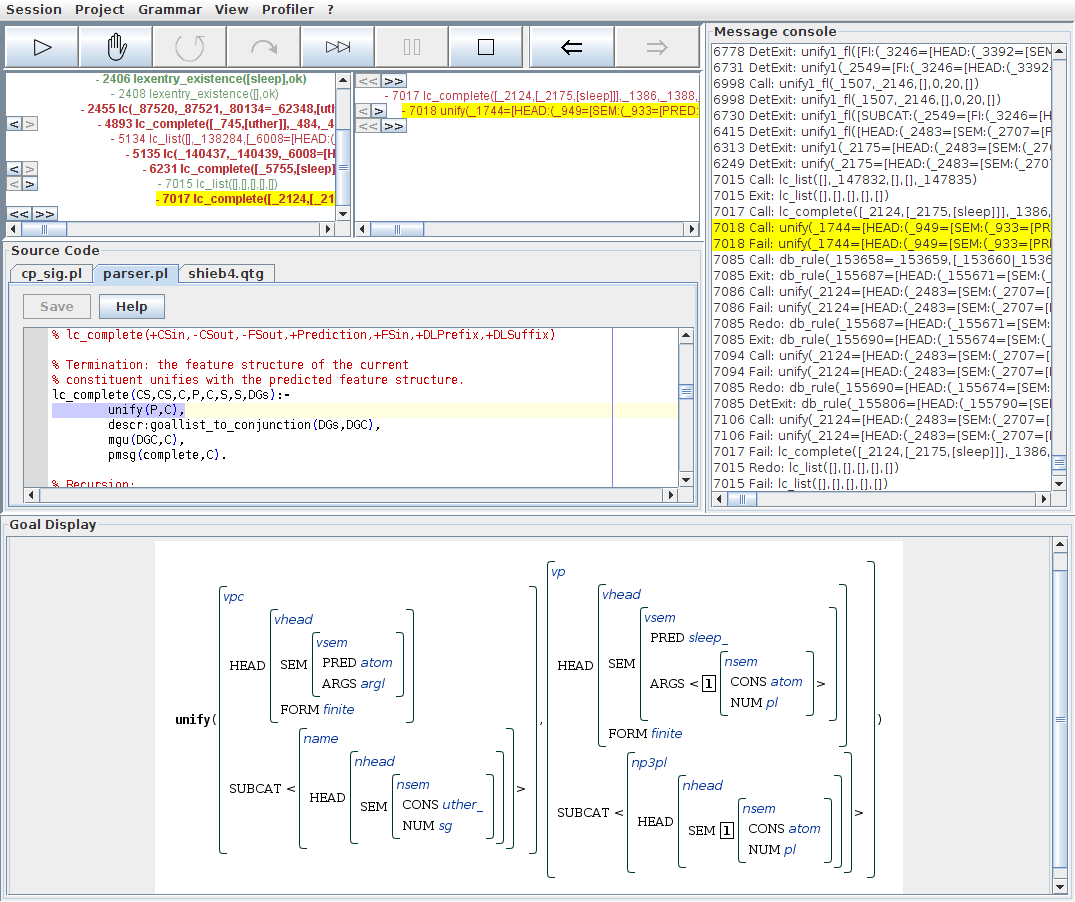
The reader may find it instructive to continue browsing the search tree around and beyond this point. The non-terminating clauses of the last lc_complete/8 have of course been tried next, and this has involved throwing in further rule applications. Further exploring this part of the search tree, the reader will see how QType unsuccessfully attempted to derive another noun phrase, and how an attempt to find a verb phrase with a complement failed because the input had already been consumed.
Chart Display

A recent addition to Kahina for QType is a chart display whose main purpose is to give a bird's eye overview of the parse by visualizing all attempts to parse constituents, and how these attempts are interrelated. Unlike in other grammar engineering systems, QType's left-corner parser does not use a chart for dynamic programming, which means that the chart presented in this view is virtual, it merely symbolizes the parsing steps taken by QType's parser, including all the steps that would be redundant if a real chart were used.
The edges on this chart represent predictions as well as attempted complete operations in QType's overall left-corner parsing strategy. Edges range over parts of the input sentence, and are grouped in a hierarchical structure that mirrors the structure of the parsing process. The color coding for the edges on the chart reflects the colors used in the step tree to symbolize successful and failed predicate calls. Edges that correspond to failed parsing steps are colored in red, and successful parsing steps are represented by edges colored in dark green. Each edge is linked to the step where its success or failure was determined, making the chart a powerful tool for quick access to the relevant portions of the step tree. In practice, you are much more likely to navigate the step tree via the chart instead of the manual approach we introduced so far.
The image to the left displays the complete chart for our example sentence "uther sleeps" after the parse has been processed. For ease of discussion, every edge in the chart has a numeric ID next to the edge label. Because these internal IDs do not contain any interesting information, the release version of Kahina for QType does not display them by default. In the example chart, edge 35 has been selected and is therefore displayed in a brighter color.
So let us consider in detail how the parsing process we have inspected post mortem in this tutorial is mapped to the chart display. There are four different types of edges in the display, each of which corresponds to one of the QType parser's internal predicates. We start with the bottom row of the chart display, which displays the result of the initial lexentry_existence check. The two green edges with the captions name:uther and iv:sleeps indicate that this initial check was successful. The two edges are linked to the respective db_word/4 steps in the step tree, allowing you to inspect the retrieved lexical entries in the feature structure view.
These two edges are instances of the first type of edge that we will introduce, they are lexicon edges. A lexicon edge is created every time a db_word/4 goal is called. The caption of a lexical edge is of the form cat:word, displaying the category assigned to the respective word. The category value is defined as the type of the feature structure that was retrieved in the corresponding db_word/4 step. Edges that result from the part of the parsing process which builds on this structure are always placed above the corresponding lexicon edge. When a db_word/4 step is redone, another lexicon edge (possibly with a different category) is created above these edges. Examples of lexicon edges in the example chart are the edges with IDs 3, 7, and 36.
Let us proceed by considering the overall process of chart construction. Calls to the lc/2 and lc/5 predicates are represented by L-shaped parse edges. Parse edges are labeled in the format parse cat, where cat is the category of the expected category. The topmost lc/2 call corresponds to the successful parse edge with ID 2 that wraps around the entire chart except for the bottom line. This topmost parse edge always carries the label parse top. The other two parse edges in our small example chart, i.e. edges 6 and 35, correspond to lc/5 steps, and we will clarify their role after discussing the remaining two edge types.
The next type of edge that we encounter is a rule edge. These edges correspond to calls of the db_rule/4 predicate, and have labels of the form mother -> dtr1 dtr2 ..., where mother is the top-level category of the feature structure on the rule's LHS, and the dtrs are the top-level categories of all the feature structures on the rule's RHS. In our example chart, we see that the first rule that is attempted (edge 4) attempts to scan the input range between positions 0 and 2 (i.e. the entire sentence) as a sentence (s) consisting of a noun phrase (np) and a verb phrase complement (vpc). The position of this rule edge just above the lexicon edge 3 indicates that this rule was attempted while trying to integrate the structure for "uther" of type name into a complete parse of the sentence. The green color shows that this attempt was successful, and the edges contained within the span of the rule edge's inverted L-shape show how this parse was executed.
The fourth and last edge type becomes relevant when we take a look at these execution details. The next edge that is constructed (edge 5) is a unify edge with the label format np~name, indicating that a structure of type name was successfully unified with a structure of type np. Inspecting the step details for the corresponding unify/2 step, we see that the structure of type name is actually the lexical entry for uther whose retrieval was symbolized by edge 3, and that the structure of type np is the first daughter of the rule whose application is mirrored by edge 4. This is the pattern for all unify edges in the QType chart representation: the expected category is on the left side, and the category of the structure to be integrated is on the right side of the tilde sign.
In the call structure, the rule retrieval leading to edge 4 and the unify step represented by edge 5 is a child of a lc_complete call that attempts to establish a constituent starting with the structure of the lexicon edge 3, and is followed by an lc_list call that attempts to complete the RHS of the selected rule. This leads to an lc/5 subgoal that tries to establish the vpc category for the remaining input symbol. This step is represented by the parse edge 6, and is successful as well, as the green color indicates. Note that the step detail view for parse edges includes representations of the established feature and constituent structures in addition to the goal representations at the call and exit ports. In this case, the constituent structure shows us that QType has managed to analyse "sleeps" as an intransitive verb (iv), which can be analyzed as a complete verb phrase (vp), which in turn qualifies as a vpc.
So let us take a look at the internals of this parse edge. QType first retrieves a lexical entry for "sleeps" of category iv (edge 7), attempts and fails to directly unify this entry with the missing constituent (edge 8), and therefore starts to attempt rule applications. Parsing "sleeps" as a sentence fails (edge 9) because an intransitive verb cannot be analyzed as a noun phrase (edge 10), but parsing it as a vp (edge 11) succeeds because the iv structure turns out to be unifiable with the right-hand side of the unary rule vp -> v (edge 12). Building on this success, we manage to unify the resulting vp structure with the desired vp constituent (edge 13), causing our rule application (edge 5) to succeed. The remaining children of the parse edge 6 (edges 21-28) are created later while searching for alternative parses, and try to build a larger constituent around the vp structure we established in edge 13. At this stage, the simple case of the top-level lc_complete predicate applies again, successfully unifying the derived structure of type s with the predicted sentence structure (edge 14). This completes our first successful parse of the sentence.
All the remaining edges in our example chart are created during backtracking, where QType attempts to derive additional parses for the input sentence. At this point, the reader is encouraged to experiment with the interplay between the chart display and the step tree branches until a complete understanding of the chart view as a tool for post-mortem parse process inspection is achieved. Often, the step detail view will be needed to recognize the differences between parts of the chart that seem to be duplicated at first sight. Bear in mind that the chart is a simple and direct representation of what QType does under the hood, and does not try to abstract from or even optimize the internal processes, so that any superfluous step you may encounter is actually carried out by the underlying system as well. A more general description of the chart display can be found in the QType chart section of this user's manual.
Searching for Patterns
In future versions of Kahina, we are planning to support searching for interesting steps in various ways. This includes searching over string patterns in the message console as well as searching through the step database for steps associated with a given source code line. These features are expected to make post-mortem inspection a lot more efficient and enjoyable, as well as accessible to users without much knowledge of the QType system.
Further Steps
If you found the tracing process too slow or tedious so far, it is time to become acquainted with the more advanced features of Kahina. The easiest way to approach these is by following the introduction to Kahina's control agent system in QTypeTutorial4.
Attachments (14)
- uther-sleep-result.png (77.1 KB) - added by jd 6 years ago.
- control-panel.png (5.4 KB) - added by jd 6 years ago.
- uther-sleep-inspection-step001.png (88.4 KB) - added by jd 6 years ago.
- uther-sleep-inspection-step002.png (100.9 KB) - added by jd 6 years ago.
- uther-sleep-inspection-step003.png (112.9 KB) - added by jd 6 years ago.
- uther-sleep-inspection-step004.png (104.7 KB) - added by jd 6 years ago.
- uther-sleep-inspection-step005.png (93.8 KB) - added by jd 6 years ago.
- uther-sleep-inspection-step006.png (95.9 KB) - added by jd 6 years ago.
- uther-sleep-inspection-step007.png (96.0 KB) - added by jd 6 years ago.
- uther-sleep-inspection-step008.png (103.8 KB) - added by jd 6 years ago.
- uther-sleep-inspection-step009.png (119.6 KB) - added by jd 6 years ago.
- uther-sleep-inspection-step010.png (131.7 KB) - added by jd 6 years ago.
- uther-sleep-inspection-step011.png (114.1 KB) - added by jd 6 years ago.
- uther-sleeps-complete-chart.png (26.3 KB) - added by jd 6 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip